

AE
稀疏自编码
自编码器是什么?
自编码器本身就是一种BP神经网络。它是一种无监督学习算法。
我们都知道神经网络可以从任意精度逼近任意函数,这里我们让神经网络目标值等于输出值x,也就是模拟一个恒等函数:
输入等于输出,这网络有什么意义?但是,当我们把自编码神经网络加入某些限制,事情就发生了变化。如图1所示,这就是一个基本的自编码神经网络,可以看到隐含层节点数量要少于输入层节点数量。

稀疏自编码器又是什么?
更一般的,如果隐藏层节点数量很大,甚至比输入层节点数量还要多时,我们仍然可以使用自编码算法,但是这时需要加入稀疏性限制。这就是稀疏自编码器。
什么是稀疏性限制?
简单说就是要保证隐藏神经元在大多数情况下是被抑制的状态。具体表现就是sigmoid函数的输出大多数状态是0,tanh函数的输出大多数状态是-1。这样有什么好处?这样能够迫使隐藏神经元发挥最大的潜力,在很不利的条件下学习到真正的特征。
损失函数的求法:
无稀疏约束时网络的损失函数表达式如下:

稀疏编码是对网络的隐含层的输出有了约束,即隐含层节点输出的平均值应尽量为0,这样的话,大部分的隐含层节点都处于非activite状态。
怎么衡量某个隐藏神经元的激活度?
取平均就好了,假设 $ a_j^{2}(x)$ 表示在给定输入x的情况下,隐藏神经元j的激活度,那么自然就有平均激活度.
因此,此时的sparse autoencoder损失函数表达式为:

可以看出,稀疏自编码神经网络的代价函数是BP神经网络的代价函数加上一个稀疏性惩罚项。
后面那项为KL距离,其表达式如下:

“隐含层节点输出平均值”求法如下:

$\rho$ 为稀疏性参数,假如这里设为0.2,则KL散度会在 “隐含层节点输出平均值” 取0.2时得最小值0, 罚因子会有如下性质(这里取稀疏性参数为0.2):

ML系统认识
ML系统认识
emmm 先写个提纲,慢慢腾上去
1. 数据与模型
由观测数据学习出的模型 其实是一个随机变量
2. 损失函数
为什么平方损失用于回归问题,而不用于分类问题?
为什么分类问题用交叉熵损失?
3. 独立同分布
独立同分布是ML统计学基础?
4. 极大似然估计与极大后验估计
从极大似然估计推出最小二乘回归;
从极大后验估计推出岭回归;
极大后验估计与正则化
5. ML中的凸、非凸问题
6. 系统理解
最小化损失虽然是在做优化,但DL中更重要的也更难的是泛化;
(1) “请记住,在机器学习中,我们试图解决的问题总是被误导了。我们只是在优化 (拟合所拥有的数据),但实际目标是泛化 而泛化在根本上定义不清” via:François Chollet;
(2)关于深度学习的一个常见误解是,梯度下降意味着达到“全局最小化”损失的同时避免“局部最小值”。实际上,真正接近全局最小化损失的深度神经网络毫无用处(极端过拟合)” via:François Chollet;
RNN-LSTM-attention
【1】.RNN
RNN 出现的目的是来处理序列数据的。
RNN 之所以称为循环神经网路,是因为一个序列当前的输出与前面的输出有关。具体的表现形式为网络会对前面的信息进行记忆并应用于当前输出的计算中,即隐藏层之间的节点不再无连接而是有连接的,也就是说隐藏层的输入不仅包括输入层的输出还包括上一时刻隐藏层的输出。
理论上,RNN 能够对任何长度的序列数据进行处理。但是在实践中,为了降低复杂性往往假设当前的状态只与前面的几个状态相关。
【2】.CNN 和 RNN 的共享参数:
我们需要记住的是,深度学习是怎么减少参数的,很大原因就是参数共享:
CNN 是在空间上共享参数;
RNN 是在时间上(顺序上)共享参数:
【3】.RNN 几种架构
然后来说说几种用 RNN 组成的常用架构,如下图:
图1是普通的单个神经网络;
图2是把单一输入转化为序列输出;
图3是把序列输入转化为单个输出;
图4是把序列转化为序列,也就是 seq2seq 的做法;
图5是无时差的序列到序列转化,可以作为普通得语言模型。
【4】几个比较重要的架构:
(1)N to 1
输入是一个序列,输出是一个单独的值而不是序列。这种结构通常用来处理序列分类问题。如输入一段文字判别它所属的类别,输入一个句子判断其情感倾向,输入一段文档并判断它的类别等等。具体如下图:
(2) N to M
这种结构又叫 Encoder-Decoder 模型,也可以称之为 Seq2Seq 模型。在实现问题中,我们遇到的大部分序列都是不等长的,如机器翻译中,源语言和目标语言的句子往往并没有相同的长度。而 Encoder-Decoder 结构先将输入数据编码成一个上下文向量 c,之后在通过这个上下文向量输出预测序列
注意,很多时候只用上下文向量 C 效果并不是很好,而 attention 技术很大程度弥补了这点。
seq2seq 的应用的范围非常广泛,机器翻译,文本摘要,阅读理解,对话生成….,包括各种 attention,不同结构等
[3]要了解深度学习中的注意力模型,就不得不先谈Encoder-Decoder框架,因为目前大多数注意力模型附着在Encoder-Decoder框架下,当然,其实注意力模型可以看作一种通用的思想,本身并不依赖于特定框架,这点需要注意.
如果把Attention机制从上文讲述例子中的Encoder-Decoder框架中剥离,并进一步做抽象,可以更容易看懂Attention机制的本质思想。

我们可以这样来看待Attention机制(参考图9):将Source中的构成元素想象成是由一系列的< Key,Value >数据对构成,此时给定Target中的某个元素Query,通过计算Query和各个Key的相似性或者相关性,得到每个Key对应Value的权重系数,然后对Value进行加权求和,即得到了最终的Attention数值。所以本质上Attention机制是对Source中元素的Value值进行加权求和,而Query和Key用来计算对应Value的权重系数。即可以将其本质思想改写为如下公式:

参考图解RNN变体
负梯度方向-函数值下降最快的方向
将$ f(x_k+\delta)$泰勒级数展开:
$$
\begin{matrix}
f(x_k+\delta)\approx f(x_k)+f^1(x_k) \cdot\delta+1/2f^2(x_k) \cdot\delta^2+…+(1/n!) \cdot f^n(x_k) \cdot\delta^n\
\end{matrix} \tag{1}
$$
因为式(1)中后几项的值相比前几项来说比较小,比如看前三项,将前三项写为矢量形式:
$$
\begin{matrix}
f(x_k+\delta)\approx f(x_k)+ \nabla^Tf(x_k) \cdot\delta+1/2\cdot\delta^T\nabla^2f(x_k) \cdot\delta\
\end{matrix} \tag{2}
$$
看式(2)的前两项,可得:
当 $\delta = \nabla^Tf(x_k)$,也就是对于向量来说,两者方向相同时,$\nabla^Tf(x_k) \cdot\delta$取得最大值。
所以,$\delta$ 选择梯度方向,函数值最快上升;$\delta$ 选择负梯度方向,函数值最快下降。
基本排序方法
排序方法
- 堆排序
- 希尔排序
- 快速排序
- 插入排序
- 直接选择排序
- 冒泡排序
总结如下:

本篇博客所有排序为从小到大;python3。(尚未完成所有的排序。。。。)
一、冒泡排序 BubbleSort
介绍:
冒泡排序,如果您想把大的放到最后,所以从第一位开始比较(每次都与下一位比它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。)
步骤:
比较相邻的元素。如果第一个比第二个大,就交换他们两个。
对第0个到第n-1个数据做同样的工作。这时,最大的数就“浮”到了数组最后的位置上。
针对所有的元素重复以上的步骤,除了最后一个。
持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
源代码:(python实现)1
2
3
4
5
6
7
8
9
10
11# 最差版
def BubbleSort1(array):
length = len(array)
if length == 0 :
return False
else :
for i in range(length):#总共需要遍历length次,第一次排完后,最大的被排到了末位
for j in range (1,length-i):
if array[j-1] > array[j]:
array[j-1],array[j] = array[j],array[j-1]
return array
不过针对上述代码还有两种优化方案。
优化1:最差版,排序次数最多,如果中途就已经排好顺序,则没有必要在进行排序。
#即(某一趟遍历如果没有数据交换,则说明已经排好序了,因此不用再进行迭代了,用一个标记记录这个状态即可。)
优化2:记录某次遍历时最后发生数据交换的位置,这个位置之后的数据显然已经有序,不用再排序了。 因此通过记录最后发生数据交换的位置就可以确定下次循环的范围了。
优化版1、2详见这里
二、选择排序 SelectionSort
介绍:
选择排序无疑是最简单直观的排序。它的工作原理如下。
步骤:
在未排序序列中找到最小(大)元素,存放到排序序列的起始位置。
再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。
以此类推,直到所有元素均排序完毕。
源代码:(python实现)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19# 选择排序 SelectionSort
# 在未排序序列中找到最小(大)元素,存放到排序序列的起始位置。
# 再从剩余未排序元素中继续寻找最小(大)元素,然后放到 "已排序序列"的末尾。
# 以此类推,直到所有元素均排序完毕
#核心,开始时,锁定最小元素应该存放的位置:第0位。然后从余下元素中找出最小值,替换第0位
#比如a=[2,5,1,3],a[0]=2,从[5,1,3]中找出最小的是第二位元素a[2]=1,交换a的第0元素与第2元素(而不是每次都与a[0]比较,得:【1,5,2,3】
#=从小到大排列=============================================================================
def SelectionSort(array):
length = len(array)
if length == 0 :
return False
else :
for i in range(0,length):
mini =i#此次遍历的min值在数组中的位置
for j in range(i+1,length):
if array[j] > array[mini]:
mini=j #此次比较产生了更小的值,记录它的下标
array[j],array[mini] = array[mini],array[j]
return array
三、插入排序 InsertionSort
1.从第一个元素开始,该元素可以认为已经被排序
2.取出下一个元素,在已经排序的元素序列中从后向前扫描
3.如果被扫描的元素(已排序)大于新元素,将该元素后移一位
4.重复步骤3,直到找到已排序的元素小于或者等于新元素的位置
5.将新元素插入到该位置后
重复步骤2~5。
操作过程示意图:
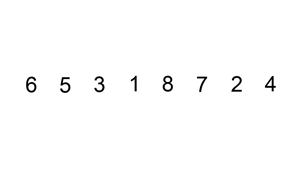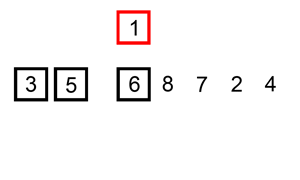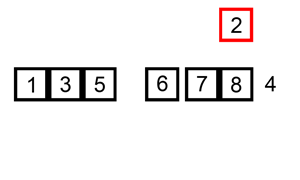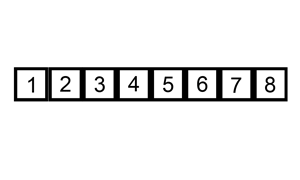
#插入排序的工作原理是,对于每个未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入
def InsertionSort(array):
length = len(array)
if length == 0 :
return False
else :
for i in range(1,length):#每个未排序数据
if array[i]<array[i-1]:
mini=array[i]#给array[i]找到合适的插入位置
index=i
for j in range (i-1,-1,-1):#和已排序序列比较
if array[j] > mini:
array[j+1] = array[j]
index = j #目前最合适的插入位置
else :
break
array[index]=mini#和已排序序列比较完了,将array[i]插入合适位置
return array
四、希尔排序 ShellSort
【1】介绍:
希尔排序,也称递减增量排序算法,实质是分组插入排序。由 Donald Shell 于1959年提出。希尔排序是非稳定排序算法。
希尔排序的基本思想是:将数组列在一个表中并对列分别进行插入排序,重复这过程,不过每次用更长的列(步长更长了,列数更少了)来进行。最后整个表就只有一列了。将数组转换至表是为了更好地理解这算法,算法本身还是使用数组进行排序。
【2】例如
假设有这样一组数[ 13 14 94 33 82 25 59 94 65 23 45 27 73 25 39 10 ],如果我们以步长为5开始进行排序,我们可以通过将这列表放在有5列的表中来更好地描述算法,这样他们就应该看起来是这样:
13 14 94 33 82
25 59 94 65 23
45 27 73 25 39
10
然后我们对每列进行排序:
10 14 73 25 23
13 27 94 33 39
25 59 94 65 82
45
将上述四行数字,依序接在一起时我们得到:[ 10 14 73 25 23 13 27 94 33 39 25 59 94 65 82 45 ]。这时10已经移至正确位置了,然后再以3为步长进行排序:
10 14 73
25 23 13
27 94 33
39 25 59
94 65 82
45
排序之后变为:
10 14 13
25 23 33
27 25 59
39 65 73
45 94 82
94
最后以1步长进行排序(此时就是简单的插入排序了)。
CNN推导+反向传播
卷积神经网络过程详解–wangafufu
DeepLearning
总共分四部分介绍:
本文主要目的,整体把握卷积神经网络的细节。
感觉网上介绍细节的很多,不知道整体,脾气不好的小孩,容易不开心惹,比如我。。吼吼
- 1. 特点:局部连接,权值共享。
- 2. 前向传播计算:理解多通道卷积(卷积输入的长度、宽度、深度)卷积计算和池化。
- 3. 误差项的反向传播:将损失函数先对输出层的输入值求导,得出最后一层的误差项,再利用梯度公式,寻找规律,根据最后一层的误差项反推出每一层的误差项,最后得到所有层的误差项。
- 4. 权重更新:利用每层的误差项对权重w和偏置b进行更新——损失函数对每层的filter(w1,w2,,b)求导,来更新参数。
具体如下:
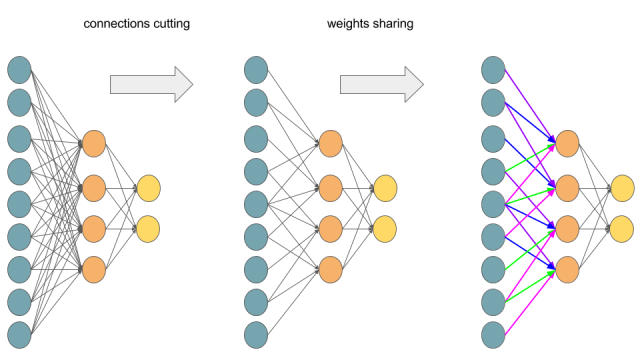
1. 特点:局部连接,权值共享。
见下图。第一个框图为全连接,每个s均与所有的x相连接,每个w值各异;第二个框图为添加’局部连接‘的示意图,每个s均与3个x相连接,减少了参数个数,例如s2拥有自己的一组权重 W2 =(w21,w22,w23,w24),W1 W2 W3 各异;在第二个框图基础上再添加’权值共享‘,则,得到W1=W2=W3,进一步减少了参数个数。
2. 前向传播–卷积运算
学会计算参数个数,就明白卷积是怎么卷的了,参考我的 多通道卷积
前向传播
深度为n=1,1 filter,所以卷积结果为1个feature map
[L层——k个filter(每个filter可以有m个卷积模板,即每个fliter的深度为m)——L+1层(k个featuer map )]
深度为n=4。2 filter,所以卷积结果为2个featuer map。
3. 误差反向传播
核心思想:
参照下图1(L、 L-1 层间的前向传播),一步一步耐心的进行梯度的链式求导。
每层的误差项:对输入值求导——损失函数对该层中每个神经元的输入值分别求导,即得到每个神经元对应的误差项。
1 | A[本层输入值a \ 激活函数f, L-1层 * ] -->|*卷积*| B(卷积结果\激活函数f,L层 *) |
图1
总述:
对于每一层,将损失函数对每一个神经元的输入值a求导,即得到每一个神经元输入值的误差。下图为L、 L-1 层的误差项,中间的filter为原filter旋转180度之后的结果。并且下图为卷积时步长为1,深度为1,滤波器个数为1时对应的误差项情况;步长,深度,滤波器个数增多时,误差项可以经过不太复杂的推广得到。
前向传播时:L-1层(D个feature map)——> N个卷积核——> L层(N个feature map)
误差由L层向 L-1 层传递,传递方式:
误差(L-1)= 反转后的filter*误差(L)
L-1层(D个sensitivity map)<—— N个卷积核<—— L层(N个sensitivity map)
以此类推,计算出各层中每个神经元的误差项。

*引申:
当步长改变,深度增多,滤波器filter个数增多,L-1层的 feature map 个数增多时,要进行误差传递,就相应参考以上进行filter反转的卷积操作和多通道卷积过程;思考误差反向传播的过程时,注意每层的误差项个数与参数个数的对应相等。
引申1. 卷积步长为S时的误差传递
我们先来看看步长为S与步长为1的差别。

如上图,上面是步长为1时的卷积结果,下面是步长为2时的卷积结果。我们可以看出,因为步长为2,得到的feature map跳过了步长为1时相应的部分。因此,当我们反向计算误差项时,我们可以对步长为S的sensitivity map相应的位置进行补0,将其『还原』成步长为1时的sensitivity map,再进行滤波器反转卷积求误差。
引申2. L-1层深度为D,L层有1个卷积核时的误差传递
(1)当L-1层深度为D时(L-1层有D个feature map),filter的深度也必须为D(1个卷积核,这个卷积核对应D个卷积模板),L-1层的D个feature map分别只与对应的卷积模板进行卷积计算:
L-1层(D个feature map)——> 1个卷积核——> L层(1个feature map)
因此,
(2)反向计算误差项时,我们可以用这个卷积核对应D个卷积模板分别与L层的这一个sensitivity map进行卷积,得到L-1层的D个sensitivity map。如下图所示:
L-1层(D个sensitivity map)<—— 1个卷积核(D个卷积模板) <—— L层(1个sensitivity map)
引申3. filter数量为N时的误差传递(区分filter的数量和深度)
(1) filter数量为N时,输出层的深度也为N,第n个filter卷积产生输出层的第n个feature map。
L-1层(D个feature map)——> N个卷积核filter(每个卷积核有D个卷积模板)——> L层(N个feature map,,每个filter对应一个feature map)
因此,
(2)反向计算误差项时,
L-1层(D个sensitivity map)<—— N个卷积核filter(每个卷积核有D个卷积模板) <—— L层(N个sensitivity map)
由于第L-1层每个加权输入都同时影响了第L层所有feature map的输出值,因此,反向计算误差项时,需要使用全导数公式。也就是,我们先使用第m个filter(D个卷积模板)与对应的第L层的第m个sensitivity map进行卷积,得到D个偏sensitivity map,称这D个偏sensitivity map为一组。依次用每个filter做这种卷积,就得到N组偏sensitivity map。最后在各组之间将N个偏sensitivity map 按对应filter、对应元素相加,即得到D个sensitivity map,就是最终的L-1层的那D个sensitivity map。
引申4. 池化层的误差传播
最大池化:最大元素对应位置误差原路返回,其余位置的为误差项为零,然后反向传回
均值池化:均分误差,然后反向传回
4. 权重更新
损失函数对每层的filter中的每个w(w1,w2,,)求导,来更新参数:需要用到反向传播求出的误差项。梯度公式推导后,可以看出,求L层的w相对损失函数的梯度,实际是利用反向传播得到的L层的误差项结果、L-1层的输出值进行计算。
5. 题外话
题外话1:公式推导并不难,大家不要被吓到,只要牢记 图1 的结构,耐心利用链式求导法则,稍微调用一下高数知识即可~
题外话2:本菜菜在详细学习时,发现,公式推导不难,难的时整体把握。比如理解卷积的深度(多通道卷积)、反向传播时误差项与前向传播时权重的互相对应(毕竟,求误差项是给各个权重参数求的),利用求得的误差项进行参数更新。详细公式我在草纸上推导了,搬移公式实在太麻烦了,就不拷贝啦~
题外话3:通过本菜菜几天的研究,建议先整体把握,再去啃公式,不然容易看完不知道干什么的。
详细公式可以参考并非常感谢:此博客
Hexo+Github+next+mathJax
想要畅通无阻的美滋滋的上传博客,包括文字内容和公式,完完整整总共十大步流程,亲自折腾过的总结:
- 搭建Node.js
- 搭建Git 环境
- GitHub 注册和配置
- 安装配置 Hexo
- 关联 Hexo 与 GitHub Pages
- 发表文章
- 更换主题theme
- 多PC同步管理博客(可略过)
- 如何向Github提交代码
- 添加mathJax
- 上传图片
1. 搭建Node.js
- 在 Node.js 官网:https://nodejs.org/en/ 下载安装包 ,一路next即可.
- 然后打开命令提示符,输入
1
node -v、npm -v,
出现版本号则说明 Node.js 环境配置成功!!!
2. 搭建Git 环境
因为需要把本地的网页和文章等提交到 GitHub 上。 Git 是一款免费、开源的分布式版本控制系统,用于敏捷高效地处理任何或小或大的项目。
- 在 Git 官网:https://git-scm.com/ 下载安装包 ,安装。
桌面右键,打开 Git Bush Here,输入
1
git --version
出现版本号则说明 Git 环境配置成功,第二步完成!!!
3.GitHub 注册和配置
- 创建仓库:Repository name 使用自己的用户名,仓库名规则:
注意:yourname 必须是你的用户名: yourname/yourname.github.io - 访问 yourname.github.io,如果可以正常访问,那么 Github 的配置已经结束了。
4.安装配置 Hexo
- 我是在D盘新建了一个hexo文件夹,在这个路径D\hexo下cmd,安装一下内容的
使用 npm 安装 Hexo:在命令行中输入
1
npm install hexo-cli -g
等待安装,有warn无所谓的啦
继续输入
1
hexo version
出现版本信息,则安装OK
安装 Hexo 完成后,请执行下列命令来初始化 Hexo,用户名改成你的,Hexo 将会在指定文件夹中新建所需要的文件。
1
2
3hexo init onionwyc.github.io
cd onionwyc.github.io
npm install运行本地 Hexo 服务
1
2
3hexo server
或者
hexo s
无法打开 localhost4000
不怕,执行:1
2npm install hexo -server --save
hexo s -p 3600
- 打开http://localhost:3600/
成功出现 Hexo 界面!!激动啊
5.关联 Hexo 与 GitHub Pages
我们利用 SSH keys让本地git项目与远程的github联系起来!
右键选择 Git Bash Here, 中操作:
生成SSH keys
输入你自己的邮箱地址1
ssh-keygen -t rsa -C "onionwuyc@gmail.com"
在回车中会提示你输入一个密码,这个密码会在你提交项目时使用,如果为空 的话提交项目时则不用输入,我们按回车不设置密码。
添加 SSH Key 到 GitHub
打开 C:\Users\.ssh\id_rsa.pub,此文件里面内容为刚才生成的密钥,准确的复制这个文件的内容,粘贴到 https://github.com/settings/ssh 的 new SSH key 中
测试
可以输入下面的命令,看看设置是否成功,git@github.com的部分不要修改:1
ssh -T git@github.com
如果提示:1
Hi defnngj You've successfully authenticated, but GitHub does not provide shell access.
说明你连接成功了
如果是下面的反馈:1
2
3The authenticity of host ‘github.com (207.97.227.239)’ can’t be established.
RSA key fingerprint is 16:27:ac:a5:76:28:2d:36:63:1b:56:4d:eb:df:a6:48.
Are you sure you want to continue connecting (yes/no)?
不要紧张,输入yes就好,然后会看到:1
Hi aierui! You've successfully authenticated, but GitHub does not provide shell access.
配置Git个人信息
现在你已经可以通过 SSH 链接到 GitHub 了,还有一些个人信息需要完善的。
Git 会根据用户的名字和邮箱来记录提交。GitHub 也是用这些信息来做权限的处理,输入下面的代码进行个人信息的设置,把名称和邮箱替换成你自己的。1
2git config --global user.name "onionwyc"
git config --global user.email "onionwuyc@gmail.com"
配置 Deployment
在_config.yml文件中,找到Deployment,然后按照如下修改,用户名改成你的:
需要注意的是:冒号后面记得空一格!1
2
3
4
5
6# Deployment
## Docs: https://hexo.io/docs/deployment.html
deploy:
type: git
repo: git@github.com:onionwyc/onionwyc.github.io.git
branch: master
6.发表文章
- 进入你的博客目录,右键选择 Git Bash Here 进入命令窗口,输入下面代码:
1
hexo new "新建文章名称" #新建文章
或者1
进入你的博客目录,在 /source/_posts 文件夹下直接建立一个.md文件。
此时,在方法1所述的文件夹里便有了 新建文章名称.md 文件。
- 发布新建文章
在该博客项目文件夹下运行 Git Bash Here 命令窗口,依次输入如下代码:1
2
3
4
5
6hexo generate #生成更改
hexo deploy #将生成的更改部署到码云或者GitHub上
或者
先hexo g再执行hexo d布署
或者
也可使直接用hexo d -g
错误处理:
在执行 hexo deploy 后,出现 error deployer not found:git 的错误处理
输入代码:1
npm install hexo-deployer-git --save
再次传送:1
hexo d -g
可以直接进入onionwyc.github.io或者去自己的github中查看,发表成功!开心~
==注意==
- 部署到GitHub时,可能因为网速、被墙等原因,需要多次运行 hexo deploy ;有时候可以运行 hexo clean 后在运行上述代码。
- .md文件不要用记事本打开,建议使用具有markdown语法的程序打开,比如:s ubline text、notepad++等。也可以使用在线markdown编辑器。
- 文章已经发表,又重新更改了,先执行 hexo clean,再 hexo d -g即可
7.更换主题theme
- 官网下载新的人见人爱的next主题,官方主题库:https://hexo.io/themes/
- Hexo主题推荐使用 Next 为主题,请阅读 Next 的官方文档( http://theme-next.iissnan.com/ ),5 分钟快速安装。
- 将下载的压缩包解压至D:\hexo\onionwyc.github.io\themes下,并重名命为next
- 将 D:\hexo\onionwyc.github.io 下的站点配置文件_config中的theme项修改为
1
theme :next
输入1
hexo s --debug
进行本地测试1
hexo s -p 3600
然后就可以在http://localhost:3600/.中看到新主题
添加插件
添加 sitemap 和 feed 插件
切换到你本地的 hexo 目录 ,在命令行窗口,输入以下命令1
2npm install hexo-generator-feed -save
npm install hexo-generator-sitemap -save
修改hexo/onionwyc.github.io/ _config.yml,增加以下内容1
2
3
4
5
6
7
8
9
10
11
12# Extensions
Plugins:
- hexo-generator-feed
- hexo-generator-sitemap
#Feed Atom
feed:
type: atom
path: atom.xml
limit: 20
#sitemap
sitemap:
path: sitemap.xml
再执行以下命令,部署服务端1
hexo d -g
配完之后,就可以访问 https://onionwyc.github.io/atom.xml 和 https://onionwyc.github.io/sitemap.xml ,发现这两个文件已经成功生成了。
访问https://onionwyc.github.io 可以看到主题已经更改。
每次更改主题配置中的内容后,执行下列命令即可:1
2hexo clean #清除缓存
hexo d -g #部署到服务端
8.多PC同步管理博客
很多人可能家里一台笔记本,公司一个台式机,想两个同时管理博客,同时达到备份的博客主题、文章、配置的目的。下面就介绍一下用github来备份博客并同步博客。
A电脑备份博客内容到github
配置.gitignore文件。进入博客目录文件夹下,找到此文件,用sublime text 打开,在最后增加两行内容/.deploy_git和/public初始化仓库。
在博客根目录下,在git bash下依次执行git init和git remote add origin 为远程仓库地址。同步到远程仓库。
gitbash下依次执行以下命令1
2
3git add . #添加目录下所有文件
git commit -m "更新说明" #提交并添加更新说明
git push -u origin master #推送更新到远程仓库B电脑拉下远程仓库文件
在B电脑上同样先安装好node、git、ssh、hexo,然后建好hexo文件夹,安装好插件,(然后选做:将备份到远程仓库的文件及文件夹删除),然后执行以下命令:
1 | git init |
发布博客后同步
在B电脑发布完博客之后,记得将博客备份同步到远程仓库
执行以下命令:
1 | git add . |
平时同步管理
每次想写博客时,先执行:git pull进行同步更新。发布完文章后同样按照上面的 发布博客后同步 同步到远程仓库。
- 中文乱码
在 md 文件中写中文内容,发布出来后为乱码,原因是 md 的编码不对,将 md 文件另存为UTF-8编码的文件即可解决问题。
主要参考并感谢 此作者
9. 如何向Github提交代码
在Github新建一个仓库:点击右上角的New repository新建仓库,输入仓库名称,然后创建仓库就可以了。
仓库创建好了之后,按右侧按钮复制SSH地址
- 一切准备就绪,接下来就是Git的事了,首先进入想要上传到GitHub的项目的文件夹下,创建好本地仓库,将想要上传的文件先添加到本地仓库中。
1
git init
1 | git add |
1 | git commit -m "first commit" |
接下来将本地仓库与远程仓库取得关联,使用git remote add origin + 此次的SSH。例如:
1
git remote add origin git@github.com:onionwyc/confusion_matrix.git
最后在通过以下命令将代码push到GitHub。
1
git push -u origin master
接下来刷新GitHub就可以看到刚刚提交上去的代码了。
10.添加mathJax
注意!!开始不知道为什么,传送的公式全都无法显示,后经本菜菜多方查证,原来hexo不支持公式。。。
原生hexo并不支持数学公式,需要安装插件 mathJax。
【1】 安装与配置mathJax
1 | $ npm install hexo-math --save |
在站点配置文件 _config.yml 中添加:1
2
3
4
5
6math:
engine: 'mathjax' # or 'katex'
mathjax:
# src: custom_mathjax_source
config:
# MathJax config
在 next 主题配置文件中 themes/next/_config.yml 中将 mathJax 设为 true:1
2
3
4
5# MathJax Support
mathjax:
enable: true
per_page: false
cdn: //cdn.mathjax.org/mathjax/latest/MathJax.js?config=TeX-AMS-MML_HTMLorMML
【2】关于公式和矩阵的语法:
- (1)矩阵
1
2
3
4
5
6$$
\begin{bmatrix}
cos(\theta) & -sin(\theta) \\\\ #注意,hexo写矩阵时只用两个斜杠,会出错,虽然mardown中是正确的。
sin(\theta) & cos(\theta)
\end{bmatrix} \tag{2}
$$
显示为:
$$
\begin{bmatrix}
cos(\theta) & -sin(\theta) \\
sin(\theta) & cos(\theta)
\end{bmatrix} \tag{2}
$$
- (2)独占一行的公式
1
2$$ A=a \bullet i+b \bullet j=[i,j] \bullet [a;b]=基\bullet坐标 \tag{3}$$
#去掉\tag{ },则不显示标签
显示为:
$$ A=a \bullet i+b \bullet j=[i,j] \bullet [a;b]=基\bullet坐标 \tag{3}$$
注意,如何偷懒将乘号 $ \bullet$ (代码为 \bullet )写为 * ,整个公式将惨遭毁灭,我就是在这里卡住了很久,所以,规范符号用法,用什么查什么。
- (3) 行间的公式
1
我们都知道 $9 = 3 \times 3$
显示为:
我们都知道 $9 = 3 \times 3$
更多语法,我是参考的流程图语法参考
11. 上传图片
(1) 把主页配置文件_config.yml 里的post_asset_folder:这个选项设置为true
(2) 在你的hexo目录下执行这样一句话npm install https://github.com/CodeFalling/hexo-asset-image –save,这是下载安装一个可以上传本地图片的插件,来自dalao:dalao的git
(3) 等待一小段时间后,再运行hexo n “xxxx”来生成md博文时,/source/_posts文件夹内除了xxxx.md文件还有一个同名的文件夹
(4) 最后在xxxx.md中想引入图片时,先把图片复制到xxxx这个文件夹中,然后只需要在xxxx.md中按照格式引入图片(图片名最好不要用中文):
{% asset_img LINEAR.jpg this is an example image %}
OK!!!!!!!
(5) 最后检查一下,hexo g生成页面后,进入public\2018\07\26\index.html文件中查看相关字段,
可以发现,html标签内的语句是 <img src="\2018\07\26/xxxx/图片名.jpg"> ,
而不是<img src="xxxx/图片名.jpg> 。这很重要,关乎你的网页是否可以真正加载你想插入的图片。
lstm结构+参数个数计算
LSTM
个人认为明白如何计算一个网络的参数个数,对于理解一个网络的流程特别重要。

首先声明:
- 参数个数与steps无关
- $h_t$的维度与$c_t$相同
- 两个门来控制状态 $c_t$ ,一个门来控制状态 $c_t$ 对输出的影响。
- 有四个交互的层,也就是拥有四组【w,b】参数;所以$总参数个数= (w的元素个数 + b的元素个数)*4$
- 向量经过激活函数后,仍是一个向量:对向量中的每一个元
从上图中可以看出,每个交互的层的操作大致是一样的
重点:计算出w,b的维度,就计算出参数个数了。
素分别操作,主要都是
$$w\times[ ]+b$$
然后再激活函数,再与状态$c$作用,与参数有关的就是 $w\times[ ]+b$。
因为输入输出向量的维度都是我们提前规定好的,假设维度是:
$$ x:2024\times1,h维度=c维度=50\times1 $$
所以,根据公式:已知
$$ W \times [h;x]_{(2014+50\times 1)} + b =输出维度50\times 1 $$
其中$[h;x]维度=(2014+50\times 1),w、b$ 的维度是想要推出的
所以,可以根据矩阵运算中的维度对应倒推出 $w、b$ 的维度:
$$ w: 50\times2074, b:50\times1 $$
四组【w,b】,所以总参数:
$$ 4\times(50\times2074+50)= 415000 $$