卷积神经网络过程详解–wangafufu
DeepLearning
总共分四部分介绍:
本文主要目的,整体把握卷积神经网络的细节。
感觉网上介绍细节的很多,不知道整体,脾气不好的小孩,容易不开心惹,比如我。。吼吼
- 1. 特点:局部连接,权值共享。
- 2. 前向传播计算:理解多通道卷积(卷积输入的长度、宽度、深度)卷积计算和池化。
- 3. 误差项的反向传播:将损失函数先对输出层的输入值求导,得出最后一层的误差项,再利用梯度公式,寻找规律,根据最后一层的误差项反推出每一层的误差项,最后得到所有层的误差项。
- 4. 权重更新:利用每层的误差项对权重w和偏置b进行更新——损失函数对每层的filter(w1,w2,,b)求导,来更新参数。
具体如下:
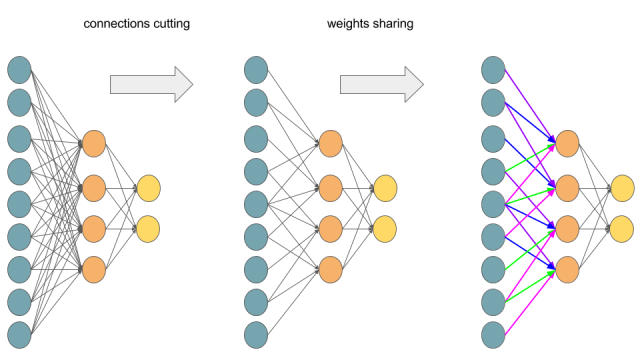
1. 特点:局部连接,权值共享。
见下图。第一个框图为全连接,每个s均与所有的x相连接,每个w值各异;第二个框图为添加’局部连接‘的示意图,每个s均与3个x相连接,减少了参数个数,例如s2拥有自己的一组权重 W2 =(w21,w22,w23,w24),W1 W2 W3 各异;在第二个框图基础上再添加’权值共享‘,则,得到W1=W2=W3,进一步减少了参数个数。
2. 前向传播–卷积运算
学会计算参数个数,就明白卷积是怎么卷的了,参考我的 多通道卷积
前向传播
深度为n=1,1 filter,所以卷积结果为1个feature map
[L层——k个filter(每个filter可以有m个卷积模板,即每个fliter的深度为m)——L+1层(k个featuer map )]
深度为n=4。2 filter,所以卷积结果为2个featuer map。
3. 误差反向传播
核心思想:
参照下图1(L、 L-1 层间的前向传播),一步一步耐心的进行梯度的链式求导。
每层的误差项:对输入值求导——损失函数对该层中每个神经元的输入值分别求导,即得到每个神经元对应的误差项。
1 | A[本层输入值a \ 激活函数f, L-1层 * ] -->|*卷积*| B(卷积结果\激活函数f,L层 *) |
图1
总述:
对于每一层,将损失函数对每一个神经元的输入值a求导,即得到每一个神经元输入值的误差。下图为L、 L-1 层的误差项,中间的filter为原filter旋转180度之后的结果。并且下图为卷积时步长为1,深度为1,滤波器个数为1时对应的误差项情况;步长,深度,滤波器个数增多时,误差项可以经过不太复杂的推广得到。
前向传播时:L-1层(D个feature map)——> N个卷积核——> L层(N个feature map)
误差由L层向 L-1 层传递,传递方式:
误差(L-1)= 反转后的filter*误差(L)
L-1层(D个sensitivity map)<—— N个卷积核<—— L层(N个sensitivity map)
以此类推,计算出各层中每个神经元的误差项。

*引申:
当步长改变,深度增多,滤波器filter个数增多,L-1层的 feature map 个数增多时,要进行误差传递,就相应参考以上进行filter反转的卷积操作和多通道卷积过程;思考误差反向传播的过程时,注意每层的误差项个数与参数个数的对应相等。
引申1. 卷积步长为S时的误差传递
我们先来看看步长为S与步长为1的差别。

如上图,上面是步长为1时的卷积结果,下面是步长为2时的卷积结果。我们可以看出,因为步长为2,得到的feature map跳过了步长为1时相应的部分。因此,当我们反向计算误差项时,我们可以对步长为S的sensitivity map相应的位置进行补0,将其『还原』成步长为1时的sensitivity map,再进行滤波器反转卷积求误差。
引申2. L-1层深度为D,L层有1个卷积核时的误差传递
(1)当L-1层深度为D时(L-1层有D个feature map),filter的深度也必须为D(1个卷积核,这个卷积核对应D个卷积模板),L-1层的D个feature map分别只与对应的卷积模板进行卷积计算:
L-1层(D个feature map)——> 1个卷积核——> L层(1个feature map)
因此,
(2)反向计算误差项时,我们可以用这个卷积核对应D个卷积模板分别与L层的这一个sensitivity map进行卷积,得到L-1层的D个sensitivity map。如下图所示:
L-1层(D个sensitivity map)<—— 1个卷积核(D个卷积模板) <—— L层(1个sensitivity map)
引申3. filter数量为N时的误差传递(区分filter的数量和深度)
(1) filter数量为N时,输出层的深度也为N,第n个filter卷积产生输出层的第n个feature map。
L-1层(D个feature map)——> N个卷积核filter(每个卷积核有D个卷积模板)——> L层(N个feature map,,每个filter对应一个feature map)
因此,
(2)反向计算误差项时,
L-1层(D个sensitivity map)<—— N个卷积核filter(每个卷积核有D个卷积模板) <—— L层(N个sensitivity map)
由于第L-1层每个加权输入都同时影响了第L层所有feature map的输出值,因此,反向计算误差项时,需要使用全导数公式。也就是,我们先使用第m个filter(D个卷积模板)与对应的第L层的第m个sensitivity map进行卷积,得到D个偏sensitivity map,称这D个偏sensitivity map为一组。依次用每个filter做这种卷积,就得到N组偏sensitivity map。最后在各组之间将N个偏sensitivity map 按对应filter、对应元素相加,即得到D个sensitivity map,就是最终的L-1层的那D个sensitivity map。
引申4. 池化层的误差传播
最大池化:最大元素对应位置误差原路返回,其余位置的为误差项为零,然后反向传回
均值池化:均分误差,然后反向传回
4. 权重更新
损失函数对每层的filter中的每个w(w1,w2,,)求导,来更新参数:需要用到反向传播求出的误差项。梯度公式推导后,可以看出,求L层的w相对损失函数的梯度,实际是利用反向传播得到的L层的误差项结果、L-1层的输出值进行计算。
5. 题外话
题外话1:公式推导并不难,大家不要被吓到,只要牢记 图1 的结构,耐心利用链式求导法则,稍微调用一下高数知识即可~
题外话2:本菜菜在详细学习时,发现,公式推导不难,难的时整体把握。比如理解卷积的深度(多通道卷积)、反向传播时误差项与前向传播时权重的互相对应(毕竟,求误差项是给各个权重参数求的),利用求得的误差项进行参数更新。详细公式我在草纸上推导了,搬移公式实在太麻烦了,就不拷贝啦~
题外话3:通过本菜菜几天的研究,建议先整体把握,再去啃公式,不然容易看完不知道干什么的。