L0/L1/L2范数
DeepLearning
包含三部分:
- 范数的应用
- 范数的概念
[ ] 详解L1/L2范数的作用及原因
范数的应用
[1] 作为正则化中的惩罚项
在机器学习中正则化是指在损失函数中通过引入一些额外的信息,来防止ill-posed问题或过拟合问题。一般这些额外的信息是用来对模型复杂度进行惩罚(Occam’s razor)。其一般形式如下:
便可以选取L1或是L2范数来作为惩罚项,不同的模型,其损失函数也不同,对于线性回归而言,如果惩罚项选择L1,则是我们所说的Lasso回归,而L2则是Ridge回归。
[2] 贝叶斯先验
正则化项从贝叶斯学习理论的角度来看,其相当于一种先验函数。即当你训练一个模型时,仅仅依靠当前的训练集数据是不够的,为了实现更好的预测(泛化)效果,我们还应该加上先验项。而L1则相当于设置一个Laplacean先验,去选择MAP(maximum a posteriori)假设。而L2则类似于 Gaussian先验。从图可以看出,L1先验对大值和小值的tolerate都很好,而L2先验则倾向于均匀化大值和小值。
如下图所示:
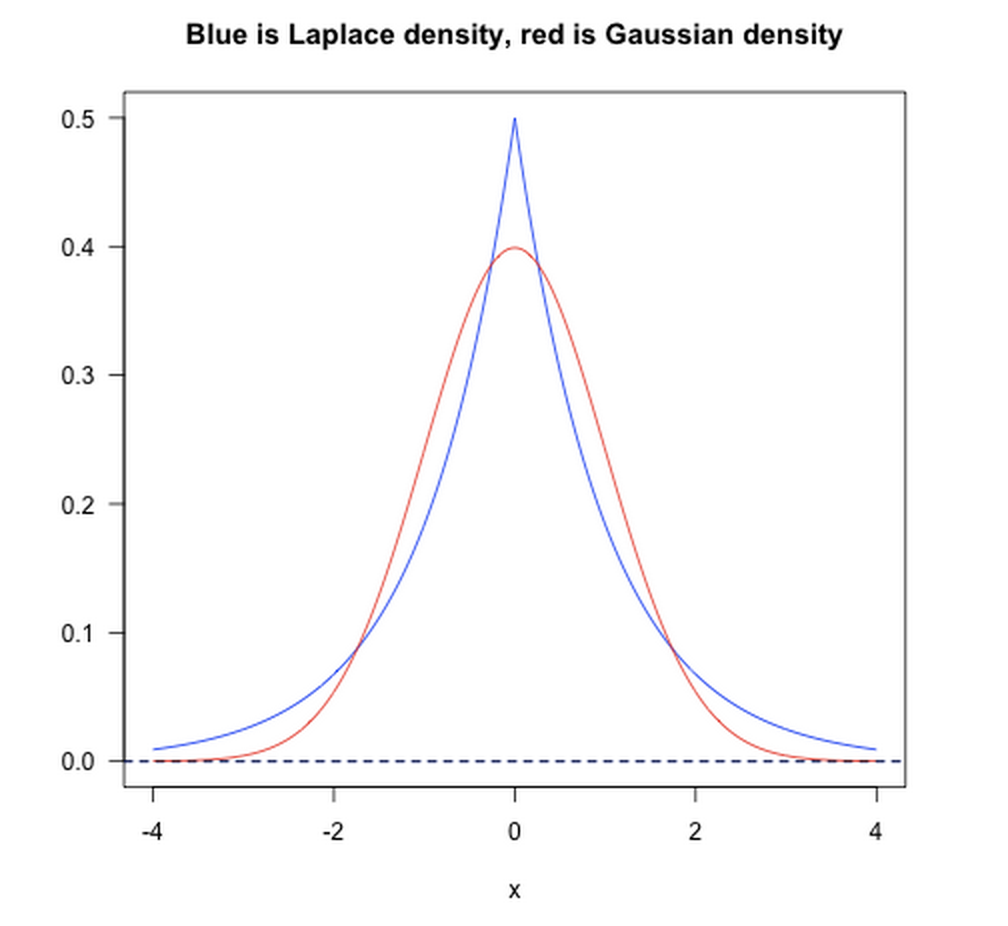
[3] 特征选择与稀疏编码
机器学习社区里通常把特征选择的方法分为三种。一种是基于统计学的一些方法,对特征进行预筛选,选出子集作为模型输入。如统计推理使用的假设检验,P值。另一种是采用某种成熟的学习算法进行特征选择,如决策树中采用信息增益来选择特征。还有一种便是在模型算法中进行自动特征选择。而L1范数作为正则化项,其特征选择的图谱倾向于spiky,实现了有效的特征选择。
稀疏编码也是想通过寻找尽可能少的特征表达某个输入的向量X。

其中 $ϕ^i$ 是所要寻找的基向量,$a_i^j$ 是我们要优化的各个基向量的权重。最右边的表达式便是其正则化惩罚项,在这里也称Sparse Cost。实际中我们通常便用L1范数。
范数的概念:
向量的范数可以简单形象的理解为向量的长度,或者向量到零点的距离,或者相应的两个点之间的距离。
向量的范数定义:向量的范数是一个函数||x||,满足非负性||x|| >= 0,齐次性||cx|| = |c| ||x|| ,三角不等式||x+y|| <= ||x|| + ||y||。
常用的向量的范数:
L1范数: ||x|| 为x向量各个元素绝对值之和;L0范数是指向量中非0的元素的个数。
如果我们用L0范数来规则化一个参数矩阵W的话,就是希望W的大部分元素都是0。L2范数: ||x||为x向量各个元素平方和的1/2次方,L2范数又称Euclidean范数或者Frobenius范数。
改善机器学习里面一个非常重要的问题:过拟合,通过L2范数,我们可以实现了对模型空间的限制,从而在一定程度上避免了过拟合。Lp范数: ||x||为x向量各个元素绝对值p次方和的1/p次方。
L∞范数: ||x||为x向量各个元素绝对值最大那个元素的绝对值,如下:

椭球向量范数: ||x||A = sqrt[T(x)Ax], T(x)代表x的转置。定义矩阵C 为M个模式向量的协方差矩阵, 设C’是其逆矩阵,则Mahalanobis距离定义为||x||C’ = sqrt[T(x)C’x], 这是一个关于C’的椭球向量范数.下图给出了一个Lp球的形状随着P的减少的可视化图。
