attention
深度学习算法
参考文章 FEED-FORWARD NETWORKS WITH ATTENTION CAN SOLVE SOME LONG-TERM MEMORY PROBLEMS中的注意力机制

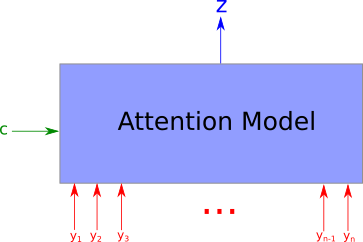
注意力模型,以n个参数 $ y_1,…,y_n$作为输入,以及上下文向量$ c $,返回一个向量$ z$,这个向量是聚焦于上下文信息的情况下对于$yi$的概要表示。更正式的,它返回的是$yi$的加权算术平均,权重是基于每个$yi$跟上下文向量$ c $的相关程度来确定的。
注意力模型的一个有趣特性是,算术平均的权重是可以获取得到并且绘制出来的,前面例子的图就是这么处理得到的,如果图像某一部分对应的权重越大,那这部分图像中的像素点会越白。
注意力模型这个黑箱子里的细节如下图所示。
这个网络看起来有些复杂,我们将会一步一步地解释。
模型的输入是下图中没有被模糊遮盖的部分,包括上下文向量$ c $和一系列的个$yi$。
接下来,模型使用一个tanh层计算得到$ m_1,…,m_n$。计算$ m_i$的输入包括上下文向量$ c $和对应的$yi$,也就是说每个$ m_i$的计算是相互独立的。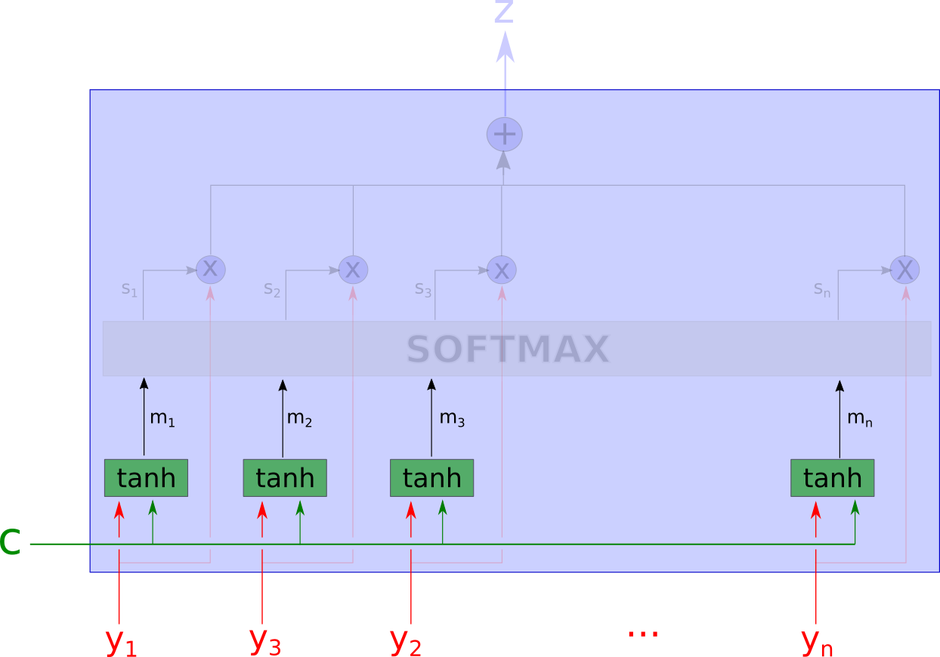
这里$ m_i$是向量。
接着,通过softmax计算得到每个权重。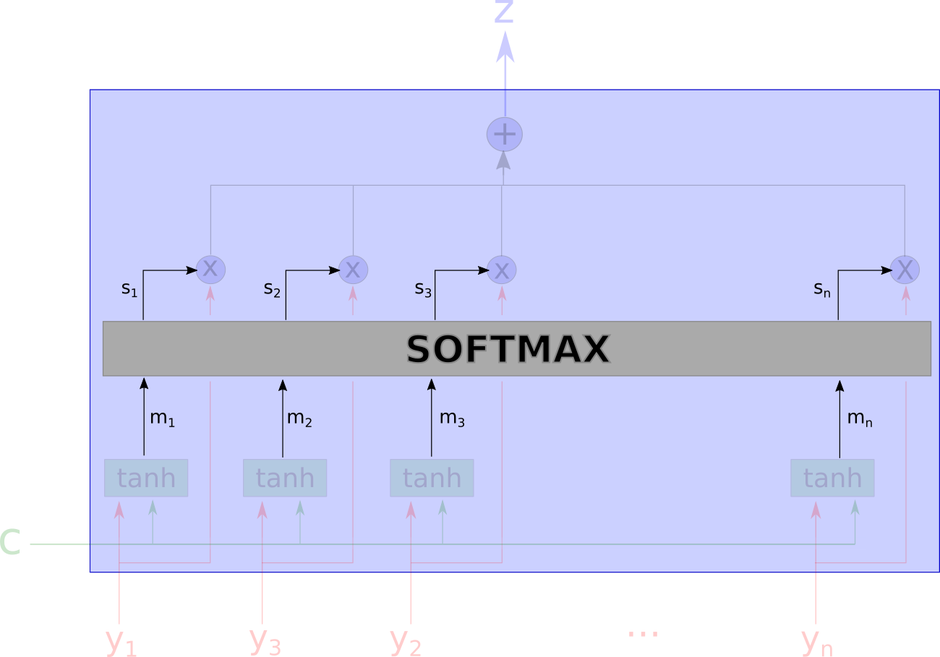
$s_1$+…+$s_i$=1
这里,$ s_i$是$ m_i$的softmax结果在学习到的方向上的投影,是一个标量。
$ w_m$是所谓的学习到的方向,用以做内积
输出$ z$是所有$y_i$的算数加权平均,权重表示每个向量跟上下文向量的相关性。